

Görüşmelerinizi yapmak için öğrenme planı ve kaynaklar dahil 20 dakika içinde öğrenin.
Kurumsal Veri ülkesinde hükmetmek için kullanılan SQL. NoSQL hareketinden önce SQL, ilişkisel veritabanlarından veri almak için kullanılan ana sorgu diliydi.
Yüksek Ölçeklenebilirlik tarafından DeveloperWeek’teki BT liderlerine 2019’da veri tabanı kullanım eğilimi hakkında bilgi veren bir ankete göre , SQL hala zamanın% 60’ından daha fazla kullanılıyor. Çoklu veritabanı stratejisi (SQL + NoSQL), zamanın% 75'inden fazlasını kullanıyor. Bu sürpriz değil. Farklı amaçlar için farklı tiplerde veritabanları kullanılır. (İlgileniyorsanız, buradan daha fazla bilgi edinebilirsiniz. )
Tüm ilişkisel veritabanlarından, MySQL kuruluşlar için en popüler veritabanı olmaya devam ediyor.
Makine öğrenmesi algoritmaları kazanan, Kaggle yarışmalarına katılan ve Panda'ları kullanarak yoğun şekilde veri kullanan Veri Bilimcileri olmak, SQL ile ilgili sorularla bir röportajda bulunmak şok edici olabilir. Ancak, olur. Hazırlanmak istiyorsun.
İlk önce
Gerçek dünyada, ilişkisel veritabanları her tür Kurumsal veriyi barındırmak için yoğun olarak kullanılmaktadır. Her tür veri kaynağından kolay erişim için veri saklanır. SQL'i bilmek, kolay veri alma ve manipülasyona neden olabilir. Veri Bilimi “yutturmaca” nın tümünden önce, Veri Bilimi büyük kuruluşlardaki İstatistikçiler tarafından yapılmıştır. Veri Madenciliği, bu İstatistikçilerin faaliyet gösterdiği istatistik ve bilgisayar biliminin kesişimidir. Veri madenciliği, büyük veri setlerindeki kalıpları keşfetmek için sadece Makine Öğrenimi ve İstatistikleri kullanan bir süreçtir.
Veri Madenciliği, analizden önce verileri aktarma veya verileri birleştirme gereksinimini ortadan kaldırır. Anında birçok veri deposunda analiz yapılabilir.
Veri Madenciliği için, Enterprise Technology'de büyük veri kümeleri genellikle SAS kullanılarak işlenir. SAS, Veri Bilim İnsanlarının çok fazla kod yazmak zorunda kalmadan büyük miktarda veri üzerinde istatistiksel analiz yapmasını sağlar. SAS'taki yerleşik işlevler, tüm veri analizi türleri için güçlüdür. SQL, SAS'ta çalıştırmak için kolayca sarılabilir. SAS komutlarının sözdizimi de SQL'e benzer.
Oracle'dan DataMiner, Enterprise Science for Data Science'da kullanılan popüler bir Veri Tabanı Madenciliği yazılımıdır. Sınıflandırma, tahmin, regresyon, ilişkilendirme, özellik çıkarma, vb. Gibi ilişkisel veritabanlarında yer alan büyük veri kümelerinde gerçekleştirilebilecek bir dizi veri analizi algoritması içerir.

İlişkisel Veri Tabanı Kavramları
SQL'e dalmadan önce, sizin için arka planı belirleyen birkaç ilişkisel veritabanı (RDBMS) kavramı vardır.
Şema
Veri tabanı şeması verilerin düzenlenmesine atıfta bulunur. Veritabanının nasıl inşa edildiğinin bir planıdır. RDBMS'de, veritabanı modeli şema tarafından uygulanmaktadır. Varlık-ilişki modelidir.
İşte bu ilişkiyi açıklayan iyi bir blog yazısı.
tablo
Şemanın ana birimlerinden biri tablodur. RDBMS'de tablolar farklı tür ilişkilerde (bire bir, çok çok, çok çok) ilişkilerde ortaya konmuş ve birbirleriyle ilişkilendirilmiştir.
Sütunlar
Tabloların dikey bölümlerine sütun denir. RDBMS'de, bir sütuna genellikle bir öznitelik de denir.
Satırlar
Tabloların yatay bölümlerine satırlar denir. RDBMS'de, bir satır çoğu zaman bir demet olarak da adlandırılır.
endeksleri
RDBMS'de, dizin verileri hızla bularak tablonun çalışmasını iyileştiren bir veri yapısıdır. Dizin türüne bağlı olarak, bir dizin oluşturarak, daha kolay erişim için sunucuda bulunan belirli bir şekilde sıralanan verilerin kopyalarını oluşturabilirsiniz. Bazen, verilerin kopyaları yerine, veriler optimize edilmiş alım için oluşturulduğunda dizin tarafından belirli bir şekilde sipariş edilebilir.
İki ana dizin türü vardır: Kümelenmemiş ve kümelenmiş.
- Kümelenmemiş dizin , verilerin keyfi bir sırayla depolanması, ancak mantıksal sıranın dizin tarafından belirtilmesidir.
- Kümelenmiş dizin , verilerin saklandığı veri bloğunun dizin tarafından farklı bir sırayla eşleşmesi için değiştirildiği zamandır.
Kümelenmemiş dizin ve Kümelenmiş dizin arasındaki farkı açıklayan bir blog yazısı.
SQL İfadeleri
SQL, RDBMS veritabanları için Yapılandırılmış Sorgu Dili'dir. Veri alırken, verileri almak için genellikle SQL deyimlerini kullanırsınız. SQL ifadeleri kullanarak farklı amaçlardan doğru veri türlerini seçmek için tabloları birleştirebilirsiniz.
Saklı yordam
SQL ifadelerinizi anında çalıştırmak yerine, "saklı yordamlar" adı verilen bir dizi program oluşturmak isteyebilirsiniz. Argümanları tıpkı bir işlev için yaptığınız gibi iletebilirsiniz.
Sorgu Planı
Bir sorgu planı verilere erişmek için sıralı bir adımlar kümesidir. Sorgu planı, veritabanında bulunan sorgu iyileştirici tarafından belirlenir. SQL ifadeleriniz ve saklı yordamınız yalnızca verileri nasıl almak istediğinize ilişkin niyetlerinizi belirtir. Sorgu en iyi duruma getiricisi tarafından belirtilen sorgu planı, SQL ifadelerinizin veritabanı tarafından nasıl yürütüldüğüne dair adımların kesin adımlarını gösterir. Sorgu planını analiz etmek, saklı yordamlarınızı ve SQL ifadelerinizi optimize etmenin ve ayarlamanın bir yoludur.
Kısıtlamalar
Kısıtlamalar, bir RDBMS veritabanındaki veri bütünlüğünü zorlar. Verileri ve veri türünü sınırlamak için kısıtlamaları yapılandırabilirsiniz. Kısıtlamalar sütun düzeyinde veya tablo düzeyinde ayarlanabilir. Birkaç farklı kısıtlama türü olabilir: NULL DEĞİL, EŞSİZ, İLK ANAHTAR, YABANCI ANAHTAR, KONTROL, ENDEKS.
- Birincil Anahtar - Tablodaki her kaydı benzersiz olarak tanımlayan kısıtlamadır. Genellikle benzersiz kayıt kimliğidir.
- Yabancı Anahtar - Bir ebeveyn-çocuk ilişkisinin bir tabloda kurulmasına izin veren kısıtlamadır. Genellikle yabancı anahtarlı tablo alt tabla iken yabancı olmayan tablo ana tablodur.
İşte Yabancı anahtarların ve Birincil anahtarların MySQL veritabanındaki ilişkilerini açıklayan iyi bir blog yazısı.
normalleştirme
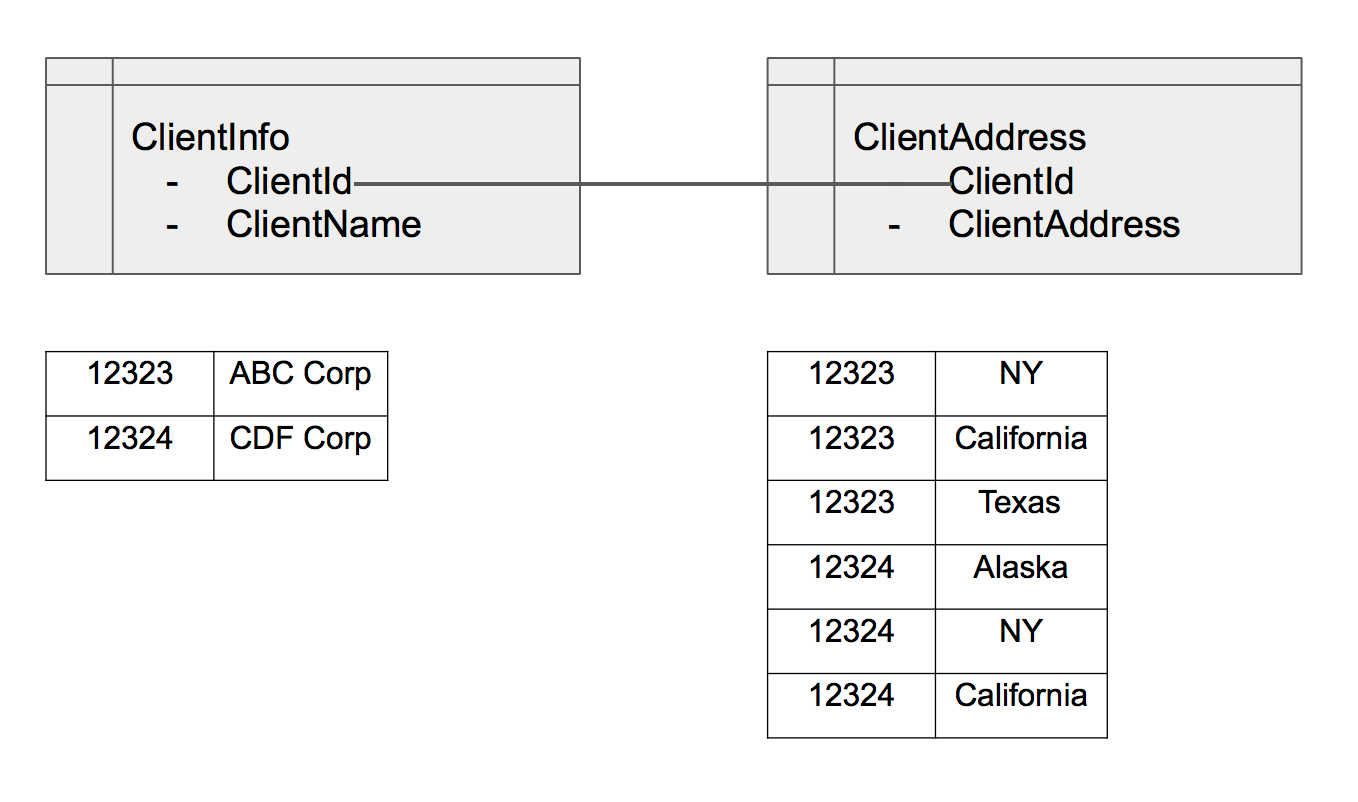
Normalleştirme, RDBMS veritabanınızdaki verileri verimli bir şekilde düzenleme işlemidir. Fikir gereksiz verileri ortadan kaldırmaktır. Örneğin, bir ClientInfo tablonuz varsa, istemcinizin verileri normalleştirmek için üç farklı adresi vardır, müşteri bilgilerini ClientId tarafından endekslenen ClientInfo adlı bir tabloda saklamak istersiniz. Ardından, üç farklı adresi ClientId bulunan bir ClientAddress tablosunda depolamak istiyorsunuz. Bundan sonra, iki tabloyu ClientId ile birlikte ilişkilendirebilirsiniz. Her tabloda “benzersiz” veri sağlayarak, depolama alanından tasarruf edebilir ve performans için optimize edebilirsiniz. (Her neyse, fikir bu.)

MySQL Veritabanını Ayarlama
MySQL veritabanını ayarlamak çok kolaydır. Sadece yürütülebilir dosyayı Mac'inize veya PC'nize indirin ve yürütülebilir dosyayı yüklemek için çalıştırın.
Ardından, MySQL istemcisini kullanarak sunucuya bağlanın.
İşte izleyebileceğiniz talimatlar.
Tabloları Oluşturmak
Aşağıdaki sorgu, bir birincil anahtar ile tabloyu oluşturur.
CREATE TABLE ClientInfo ( ClientId INT NULL DEĞİL Müşteri Adı VARCHAR (255) PRIMARY KEY (ClientId) );
Tablolardan Veri Alma
Aşağıdaki sorgu bir tablodan veri alır.
SELECT * ClientInfo'dan
Aşağıdaki sorgu iç birleştirmeyle iki tablodan veri alır:
Çıktı, hem ClientInfo hem de ClientAddress tablosunun örtüşmesini temsil eden tüm kayıtlar olacaktır.
SELECT *, ClientInfo içinden
INNER JOIN ClientAddress
ON
ClientInfo.ClientId = ClientAddress.ClientId
Aşağıdaki sorgu iki tablodan verileri “iç” birleştirme notasyonu ile örtülü olarak alır:
Çıktı öncekinden çıktı ile aynı olacaktır.
SELECT *, ClientInfo'dan, ClientAddress
WHERE
ClientInfo.ClientId = ClientAddress.ClientId
Aşağıdaki sorgu, iki birleşimden verileri dış birleştirme ile alır:
Çıktı, ClientInfo + 'nın ClientInfo ve ClientAddress tablosunun örtüşen tüm kayıtları olacaktır.
SELECT *, ClientInfo'dan itibaren
SOL OUTER JOIN ClientAddress
ON ON
ClientInfo.ClientId = ClientAddress.ClientId
Dizinler Oluşturma
Aşağıdaki sorgu bir tabloda benzersiz bir dizin oluşturur:
BENZERSİZ ENDEKSİ ClientId ON ClientInfo (ClientId) OLUŞTURMA
Sonraki adımlar
Artık MySQL tablolarıyla nasıl etkileşime gireceğiniz ve tablolardan bilgi alacağınız konusunda bir fikriniz var, işte sonraki adımlar.
- Veritabanınızdaki verilerle çalışan basit bir proje oluşturun. En kolay yol veritabanına bir dizi “kirli veri” yüklemektir. Ardından, panda kullanmak yerine SQL kullanarak veri temizleme adımlarını izleyin.
- Bundan sonra aşağıdaki referanslara biraz daha derinden ulaşabilirsiniz:
- Farklı SQL birleşimleri türleri
- Yaygın olarak kullanılan SQL fonksiyonları
- Farklı SQL indeks tipleri
- Farklı SQL veri türleri
- SQL Sorgu Performansı ve Ayarlama
Etiketler:
Teknoloji